

Kategorie: ‘Courses’
Datenbanken und Informationssysteme
Die Vorlesung “Datenbanken und Informationssysteme” gibt einen einführenden Überblick über Datenbanken und ihre Verwendung in Informationssystemen.
Data Stream Management and Analysis
In many fields today data is produced continuously, potentially unbounded, and at high rates, which is termed as data stream. Applications in smart manufacturing, aerospace, particle physics, or stock exchange trading have a high demand to handle and analyze the massive data streams created. Due to their challenging characteristics specific technologies and methods for data management and analysis have been developed. In this course, you will get a deep understanding of these principles and techniques, such as query processing and optimization or data stream mining.
Knowledge Graphs Seminar
Knowledge Graphs are large graphs used to capture information about the real world in such a way that is is useful for applications. In these data structures, there are all sorts of entities (for example, people, events, places, organizations, etc.). Knowledge Graphs are used by many organizations to represent the information they need for their operations. The most well-known example is Google, where a knowledge graph is used to enrich the search results. Also personal assistants, such as Amazon’s Alexa, Apple’s Siri and Google Now, as well as question answering systems such as IBM Watson, make use of knowledge graphs to provide information to their users.
Besides these, also other information graphs, are in use by large organizations to improve or personalize their services. Examples include the Facebook graph, the Amazon product graph, and the Thompson Reuters Knowledge Graph.
The graph also contains all sorts of information about these entities (e.g., age, opening hours, …) and relations between them (e.g., “this shop is located in Aachen”). Furthermore, it may contain context information (e.g., the source of some information) and schema information or background knowledge (e.g., “shops have opening hours”).
Deliverables of this seminar
This seminar consists of an introductory course on Knowledge Graphs. You will give a short outline presentation on your assigned topic to set overview and expectations about the paper you’re going to write. The main deliverable of the seminar is a paper that describes the state of the art of your assigned topic. While you do not need to contribute original research, your task is to show the scientific competences of literature research, presentation of a research question and understanding and putting relevant papers into context. Furthermore, you are asked to critically assess and compare strengths or challenges of existing solutions. You will review your peer’s papers and give relevant feedback to enhance your scientific writing skills. You will present your paper in a final presentation in a block seminar at the end of the semester.
Software Projektpraktikum – Building Large Language Model Applications
Mixed Reality Lab
Mixed Reality is a continuum of spatial computing experiences on virtual, augmented and extended reality devices, such as the Microsoft HoloLens 2, the HTC Vive Pro, Meta Quest 3 and Android smartphones. In this lab, we learn the basics of mixed reality software development in independent project work that student groups can propose and elaborate.
Knowledge Graph Lab SS 2025
Knowledge Graphs are large graphs used to capture information about the real world in such a way that is is useful for applications. In these data structures, there are all sorts of entities (for example, people, events, places, organizations, etc.). Knowledge Graphs are used by many organizations to represent the information they need for their operations. The most well-known example is Google, where a knowledge graph is used to enrich the search results. Also personal assistants, such as Amazon’s Alexa, Apple’s Siri and Google Now, as well as question answering systems such as IBM Watson, make use of knowledge graphs to provide information to their users.
Besides these, also other information graphs, are in use by large organizations to improve or personalize their services. Examples include the Facebook graph, the Amazon product graph, and the Thompson Reuters Knowledge Graph.
Opensource Knowledge Graphs such as Wikidata and DBPedia provide universal access to linked entities from a large range of domains.
The graph also contains all sorts of information about these entities (e.g., age, opening hours, …) and relations between them (e.g., “this shop is located in Aachen”). Furthermore, it may contain context information (e.g., the source of some information) and schema information or background knowledge (e.g., “shops have opening hours”).
In this course we will give a basic practical introduction to working with these graphs. We plan to cover the following in the course:
- Graph representation of data
- Knowledge Graph basics
- Knowledge Graph creation and maintainance tasks: Creation, Hosting, Curation and Deployment
- Use of vocabularies and ontologies as schemas for graphs
- Searching information in knowledge graphs
- Information extraction into knowledge graphs
- Data mining techniques for knowledge graphs
- Knowledge graph completion (predicting links, finding anomalies)
- Data governance aspects, e.g., data quality
- Architectures for knowledge graphs (e.g., data lakes, central vs. decentral storage, knowledge graphs on top of relational or NoSQL databases)
Knowledge Graph Lab WS 2024
Knowledge Graphs are large graphs used to capture information about the real world in such a way that is is useful for applications. In these data structures, there are all sorts of entities (for example, people, events, places, organizations, etc.). Knowledge Graphs are used by many organizations to represent the information they need for their operations. The most well-known example is Google, where a knowledge graph is used to enrich the search results. Also personal assistants, such as Amazon’s Alexa, Apple’s Siri and Google Now, as well as question answering systems such as IBM Watson, make use of knowledge graphs to provide information to their users.
Besides these, also other information graphs, are in use by large organizations to improve or personalize their services. Examples include the Facebook graph, the Amazon product graph, and the Thompson Reuters Knowledge Graph.
Opensource Knowledge Graphs such as Wikidata and DBPedia provide universal access to linked entities from a large range of domains.
The graph also contains all sorts of information about these entities (e.g., age, opening hours, …) and relations between them (e.g., “this shop is located in Aachen”). Furthermore, it may contain context information (e.g., the source of some information) and schema information or background knowledge (e.g., “shops have opening hours”).
In this course we will give a basic practical introduction to working with these graphs. We plan to cover the following in the course:
- Graph representation of data
- Knowledge Graph basics
- Knowledge Graph creation and maintainance tasks: Creation, Hosting, Curation and Deployment
- Use of vocabularies and ontologies as schemas for graphs
- Searching information in knowledge graphs
- Information extraction into knowledge graphs
- Data mining techniques for knowledge graphs
- Knowledge graph completion (predicting links, finding anomalies)
- Data governance aspects, e.g., data quality
- Architectures for knowledge graphs (e.g., data lakes, central vs. decentral storage, knowledge graphs on top of relational or NoSQL databases)
Dataspaces Proseminar
Inhalt
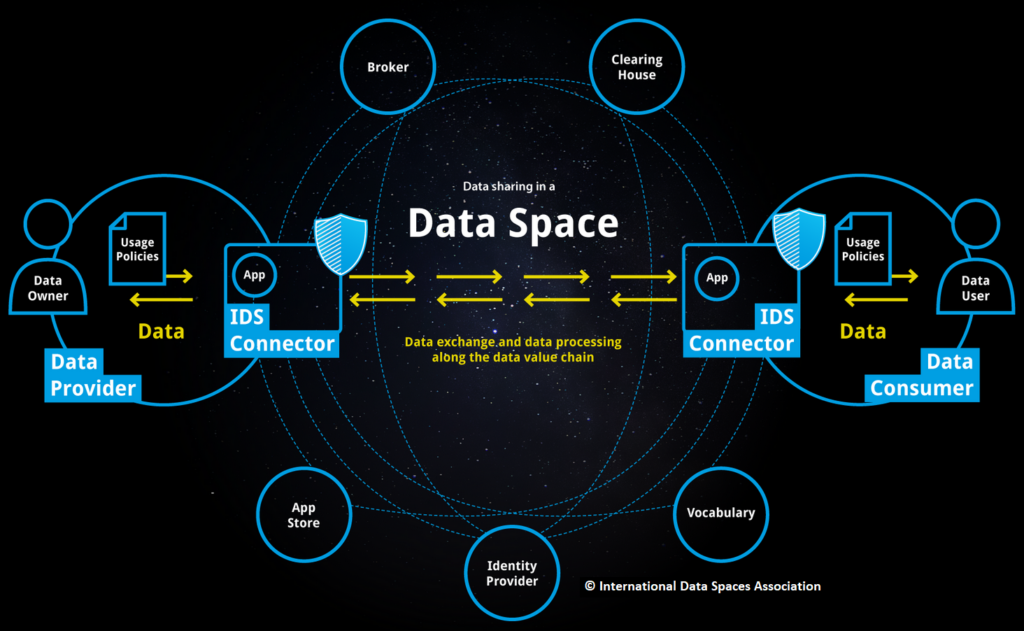
Die Anforderungen an den Datenaustausch im World Wide Web haben sich in den letzten Jahrzehnten stetig verändert. Anfangs konsumierten die Nutzer nur manuell ausgewählte Inhalte. Durch Trends wie IoT und Industrie 4.0 ist die Datenmenge exponentiell gestiegen, aber Suchmaschinen wie Google helfen dabei. Durch Social Media können Menschen auch selbst Inhalte produzieren und mit anderen teilen, allerdings meist nur über große zentrale Plattformen wie Facebook / Meta. Eine Entwicklung hin zu dezentraleren Lösungen ist seit etwa zehn Jahren im Gange, z.B. durch Blockchain. Die aktuellen Bedürfnisse im Internet sind der einfache Austausch über Domänen hinweg, Interoperabilität und vor allem Datensouveränität – also die Kontrolle über die eigenen Daten, auch wenn man sie mit anderen teilt. Dataspaces, die in Europa mit 4 bis 6 Milliarden Euro gefördert werden, adressieren genau diese Anforderungen an einen modernen Datenaustausch. In Kombination mit Semantic Web-Technologien und FAIR-Daten bieten sie vielversprechende Lösungen.
Dieses Proseminar beschäftigt sich mit Datenräumen und untersucht semantische Technologien zur Verbesserung der Dateninteroperabilität und des gemeinsamen Verständnisses. Die Inhalte umfassen grundlegende Konzepte, Prinzipien, Best Practices und Lösungen zur Verbesserung des Datenmanagements in Datenräumen.
Die Schwerpunkte dieses Proseminars sind u.a.:
- Struktur, Architektur, Entwicklung und Betrieb von Datenräumen
- Die Landschaft der > 185 existierenden Datenräume und deren Domänen
- FAIR Data, Knowledge Graphs und Linked (Open) Data als semantische Technologien für Datenräume
- Informationsmodelle als gemeinsamer Kern für die strukturierte Darstellung von Daten, Diensten, Teilnehmern und Interaktionen
- Prinzipien der Datenintegration: Verbesserung der Zugänglichkeit von Daten für verschiedene Arten von Heterogenität
- Gemeinsames Verständnis zwischen Teilnehmern: Identifikation, Vokabulare/Ontologien, Annotation, Validierung
Ablauf
Dieses Proseminar besteht aus einem Einführungskurs in Datenräume (Dataspaces). Sie halten einen kurzen Vortrag über Ihr Thema, um einen Überblick und die Erwartungen an die zu erstellende Arbeit zu vermitteln. Das Hauptergebnis des Proeminars ist eine Ausarbeitung, die den aktuellen Stand der Technik zu dem von Ihnen gewählten Thema beschreibt. Sie müssen keine eigenen Forschungsarbeiten durchführen, aber Ihre Aufgabe ist es, die wissenschaftlichen Fähigkeiten der Literaturrecherche, der Darstellung einer Forschungsfrage und des Verständnisses und der Einordnung relevanter Arbeiten in den Kontext zu demonstrieren. Darüber hinausbewerten Sie die Vor- und Nachteile bestehender Lösungen kritisch und vergleichen diese. Sie bewerten die Arbeiten Ihrer Kommilitonen (Peer-Review) und geben Feedback, um Ihre Fähigkeiten im wissenschaftlichen Schreiben zu verbessern. In einem Blockseminar am Ende des Semesters stellen Sie Ihre Arbeit in einer Abschlusspräsentation vor.